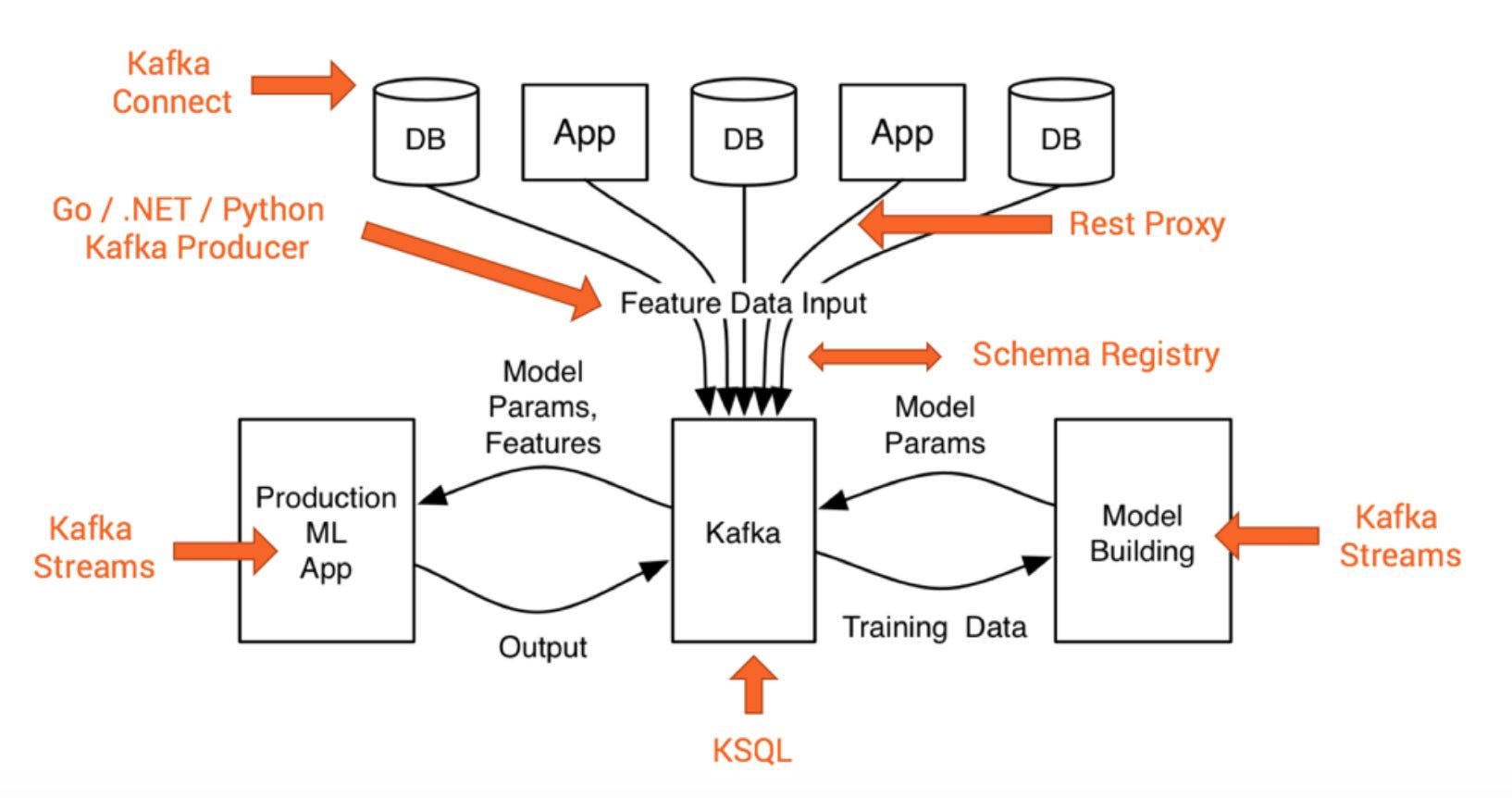
Kafka is a distributed publish-subscribe messaging system that is designed to be fast, scalable, and durable. It was developed by LinkedIn and open-sourced in the year 2011. It makes an extremely desirable option for data integration with the increasing complexity in real-time data processing challenges. It is a great solution for applications that require large-scale message processing.
Components of Kafka are :
- Zookeeper
- Kafka Cluster – which contains one or more servers called brokers
- Producer – which publishes messages to Kafka
- Consumer – which consumes messages from Kafka.
Components :
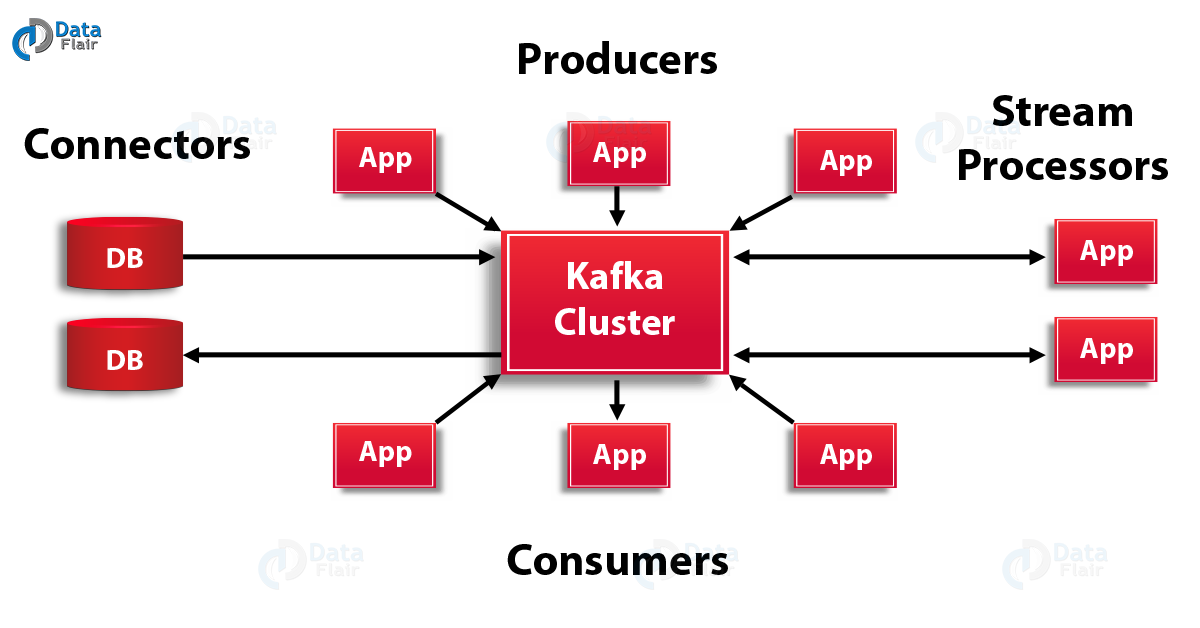
It saves messages on a disk and allows subscribers to read from it. Communication between producers, Kafka clusters, and consumers takes place with the TCP protocol. All the published messages will be retained for a configurable period of time. Each Kafka broker may contain multiple topics into which producers publish messages. Each topic is broken into one or more ordered partitions. Partitions are replicated across multiple servers for fault tolerance. Each partition has one Leader server and zero or more follower servers depending upon the replication factor of the partition.
When a publisher publishes to a Kafka cluster, it queries which partitions exist for that topic and which brokers are responsible for each partition. Publishers send messages to the broker responsible for that partition (using some hashing algorithm).
Consumers keep track of what they consume (partition id) and store it in Zookeeper. In case of consumer failure, a new process can start from the last saved point. Each consumer in the group gets assigned a set of partitions to consume from.
Producers can attach key with messages, in which all messages with same key goes to same partition. When consuming from a topic, it is possible to configure a consumer group with multiple consumers. Each consumer in a consumer group will read messages from a unique subset of partitions in each topic they subscribe to, so each message is delivered to one consumer in the group, and all messages with the same key arrive at the same consumer.
Role of Zookeeper in –

It provides access to clients in a tree-like structure. It use ZooKeeper for storing configurations and use them across the cluster in a distributed fashion. It maintains information like topics under a broker, offset of consumers.
Steps to get started with (For UNIX):
- Download Kafka – wget http://mirror.sdunix.com/apache/kafka/0.8.2.0/kafka_2.10-0.8.2.0.tgz
- tar -xzf kafka_2.10-0.8.2.0.tgz
- cd kafka_2.10-0.8.2.0/
- nside Config folder you will see server, zookeeper config files
- Inside bin folder you will see bash files for starting zookeeper, server, producer, consumer
- Start zookeeper – bin/zookeeper-server-start.sh config/zookeeper.properties
- Start server – bin/kafka-server-start.sh config/server.properties
- creating topic –bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor <your_replication_factor> –partitions <no._of_partitions> –topic <your_topic_name>
This will create a topic with specified name and will be replicated in to brokers based on replication factor and topic will be partitioned based on partition number. Replication factor should not be greater than no. of brokers available. - view topic – bin/kafka-topics.sh –list –zookeeper localhost:2181
- delete a topic – add this line to server.properties file delete.topic.enable=true
then fire this command after starting zookeeper
bin/kafka-topics.sh –zookeeper localhost:2181 –delete –topic <topic_name> - alter a topic – bin/kafka-topics.sh –zookeeper localhost:2181 –alter –topic <topic_name>
- Start producer – bin/kafka-console-producer.sh –broker-list localhost:9092 –topic <your_topic_name> and send some messages
- Start consumer – bin/kafka-console-consumer.sh –zookeeper localhost:2181 –from-beginning –topic <your_topic_name> and view messages
If you want to have more than one server, say for ex : 4 (it comes with single server), the steps are:
- create server config file for each of the servers :
cp config/server.properties config/server-1.proeprties
cp config/server.properties config/server-2.properties
cp config/server.properties config/server-3.properties - Repeat these steps for all property files you have created with different brokerId, port.
vi server-1.properties and set following properties
broker.id = 1
port = 9093
log.dir = /tmp/kafka-logs-1 - Start Servers :
bin/kafka-server-start.sh config/server-1.properties &
bin/kafka-server-start.sh config/server-2.properties &
bin/kafka-server-start.sh config/server-3.properties &
Now we have four servers running (server, server-1,server-2,server-3)
PROGRAMMING
The program in java includes producer class and consumer class.
Producer Class :
Producer class is used to create messages and specify the topic name with an optional partition.
The maven dependency jar to be included is
We need to define properties for a producer to find brokers, serialize messages, and sends them to the partitions it wants.
Once producer sends data, if we pass an extra item (say id) via data :
ex :
before publishing data to brokers, it goes to the partition class which is mentioned in the properties and selects the partition to which data has to be published.
Consumer Class :
Topic Creation :
It is a distributed commit log service that functions much like a publish/subscribe messaging system, but with better throughput, built-in partitioning, replication, and fault tolerance.
Applications:
- Stream processing
- Messaging
- Multiplayer online game
- Log aggregation


