
Managing ML production requires a combination of data scientists (algorithm procrastinators) and operations (data architects, product owners? Yes, why not?).
Operationalizing ML solutions in on-prem or cloud environments is a challenge for the entire industry. Enterprise customers usually have a long and random software update cycle, usually once or twice a year. Therefore, it is impractical to couple the deployment of the ML model with irregular update cycles. Besides, data scientists have to deal with:
- Data governance
- Model serving & deployment
- System performance drifts
- Picking model features
- ML model training pipeline
- Setting the performance threshold
- Explainability
And data architects have enough databases and systems to develop, install, configure, analyze, test, maintain… the verb would keep on accumulating, depending on the ratio of the company’s size to the number of data architects.
This is where MLOps come in to rescue the team, solution, and the enterprise!
What is MLOps?
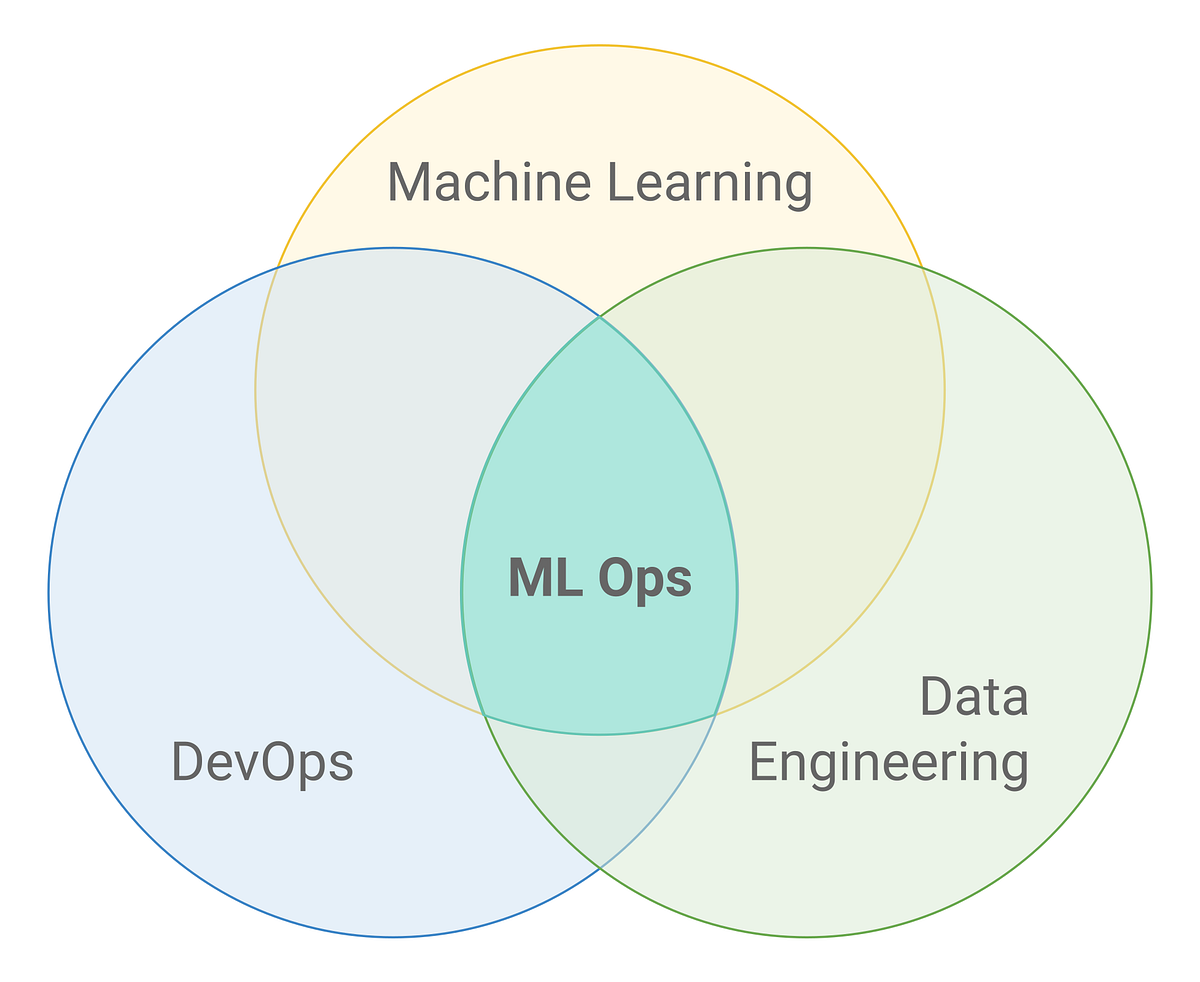
MLOps is a new coinage, and the ML community keeps on adding/ perfecting its definition (as the ML life cycle continues to evolve, its understanding is also evolving). In layman terminology, it is a set of practices/disciplines to standardize & streamline ML models in production.
MLOps Lifecycle
MLOps brings the DevOps principles to your ML workflow. It allows continuous integration into data science workflows, automates code creation and testing, helps create repeatable training pipelines, and then provides continuous deployment workflow to automate the package, model validation, and deployment to the target server. It then monitors the pipeline, infrastructure, model performance, and new data and creates a data feedback flow to restart the pipeline.

These practice involving data engineers, data scientists, and ML engineers enables the retraining of models.
All seems hunky-dory at this stage; however, in my numerous encounters with the enterprise customers, and after going through several use cases, I have seen MLOps, although evolutionary & state-of-the-art, failing several times in delivering the expected result or RoI. The foremost reason, often discovered, because of –
- The singular, unmotivated performance monitoring approach
- Unavailability of KPIs to set/measure the performance
- And lack of threshold to raising model degradation alerts
In contrast, these are the technical hindsight that is often vindictive because of the lack of MLOps standardization; However, a few business factors, such as lack of discipline, understanding, resources, can slog or disrupt your entire ML operations.


