
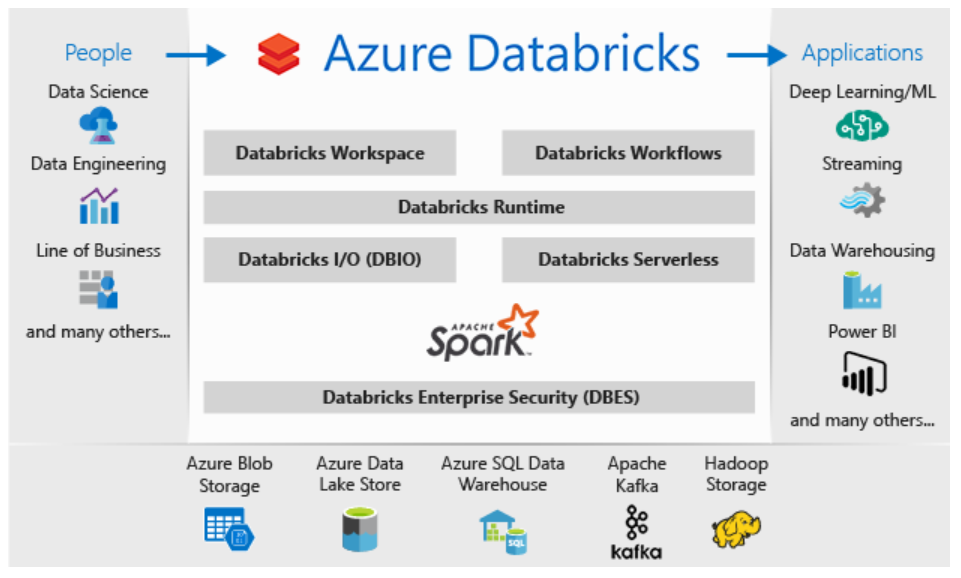
Azure Databricks, an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud, is a highly effective open-source tool, but it automatically creates resource groups and workspaces and protects them with a system-level lock, all of which can be confusing and frustrating unless you understand how and why.
The Databricks platform provides an interactive workspace that streamlines collaboration between data scientists, data engineers and business analysts. The Spark analytics engine supports machine learning and large-scale distributed data processing, combining many aspects of big data analysis all in one process.
Spark works on large volumes of data either in batch (rest) or streaming processing (live) mode. The live processing capability is how Databricks/Spark differs from Hadoop (which uses MapReduce algorithms to process only batch data).
Resource groups are key to managing the resources bound to Databricks. Typically, you specify which groups in which your resources are created. This changes slightly when you create an Azure Databricks service instance and specify a new or existing resource group. Say, for example, we are creating a new resource group, Azure will create the group and place a workspace within it. That workspace is an instance of the Azure Databricks service.
Along with the directly specified resource group, it will also create a second resource group. This is called a “Managed resource group” and it starts with the word “databricks.” This Azure-managed group of resources allows Azure to provide Databricks as a managed service. Initially this managed resource group will contain only a few workspace resources (a virtual network, a security group and a storage account). Later, when you create a cluster, the associated resources for that cluster will be linked to this managed resource group.
The “databricks-xxx” resource group is locked when it is created since the resources in this group provide the Databricks service to the user. You are not able to directly delete the locked group nor directly delete the system-owned lock for that group. The only option is to delete the service, which in turn deletes the infrastructure lock.
With respect to Azure tagging, the lock placed upon that Databricks managed resource group prevents you from adding any custom tags, from deleting any of the resources or doing any write operations on a managed resource group resource.
Example Deployment
Let’s talk a look at what happens when you create an instance of the Azure Databricks service with respect to resources and resource groups:
Steps
- Create an instance of the Azure Databricks service
- Specify the name of the workspace (here we used nwoekcmdbworkspace)
- Specify to create a new resource group (here we used nwoekcmdbrg) or choose an existing one
- Hit Create
Results
- Creates nwoekcmdbrg resource group
- Automatically creates nwoekcmdbworkspace, which is the Azure Databricks Service. This is contained within the nwoekcmdbrg resource group.
- Automatically creates databricks-rg-nwoekcmdbworkspace-c3krtklkhw7km resource group. This contains a single storage account, a network security group and a virtual network.
Click on the workspace (Azure Databricks service), and it brings up the workspace with a “Launch Workspace” button.

Launching the workspace uses AAD to sign you into the Azure Databricks service. This is where you can create a Databrick cluster or run queries, import data, create a table, or create a notebook to start querying, visualizing and modifying your data. I decided to create a new cluster to demonstrate where the resources are stored for the appliance. Here, we create a cluster to see where the resources land.

After the cluster is created, a number of resources were created in the Azure Databrick managed resource group databricks-rg-nwoekcmdbworkspace-c3krtklkhw7km. Instead of merely containing a single VNet, NSG and storage account as it did initially, it now contains multiple VMs, disks, network interfaces, and public IP addresses.
The workspace nwoekcmdbworkspace and the original resource group nwoekcmdbrg both remain unchanged as all changes are made in the managed resource group databricks-rg-nwoekcmdbworkspace-c3krtklkhw7km. If you click on “Locks,” you can see there is a read-only lock placed on it to prevent deletion. Clicking on the “Delete” button yields an error saying the lock was not able to be deleted. If you make changes to the original resource group in the tags, they will be reflected in the “databricks-xxx” resource group. But you cannot change tag values in the databricks-xxx resource group directly.

Summary
When using Azure Databricks, it can be confusing when a new workspace and managed resource group just appear. Azure automatically creates a Databricks workspace, as well as a managed resource group containing all the resources needed to run the cluster. This is protected by a system-level lock to prevent deletions and modifications. The only way to directly remove the lock is to delete the service. This can be a tremendous limitation if changes need to be made to tags in the managed resource group. However, by making changes to the parent resource group, those changes will be correspondingly updated in the managed resource group.


