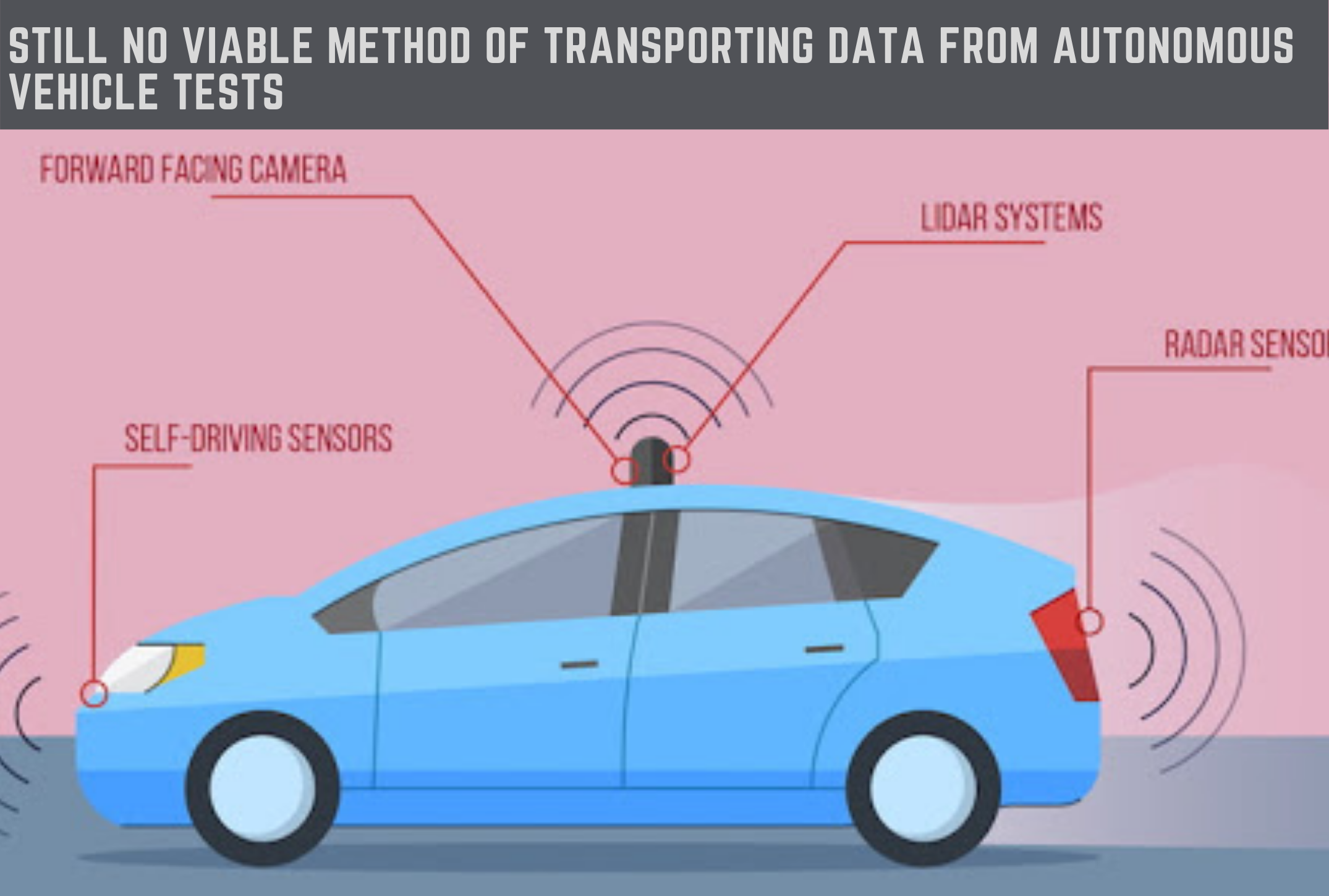
Tech companies and the auto industry are working hard in tandem to make autonomous driving a reality by the early 2020s. Driverless cars with various levels of human participation will roll out in stages over the next few years, with fully-autonomous SAE Level 5 driving on the scene by 2030.
Today, most automotive manufacturers have achieved Level 2 assisted driving where the car can manage simple scenarios, like active lane centering and parking assistance, itself. Fewer manufacturers provide Level 3 autonomous driving where the car can autonomously navigate a traffic jam or roadways to a destination. For both levels, human drivers can take the wheel if they choose.

The limitations of AI that prevent advancement to fully-autonomous driving
From an engineering standpoint, Level 3 autonomous driving is powered by two things: hard-coded structured programming models mostly written for embedded systems and deterministic rules that make decisions supported by neural networks.
These two things combine to build AI driving agents, but with at least five important limitations:
- Lack of perception and behavior intelligence compared to humans. Unlike existing AI agents trained with machine learning (ML), humans don’t need thousands of images of trees, for example, to recognize a tree or identify a driving situation.
- Low accuracy performance. With existing tools, the probability of steering accuracy decreases as more autonomous driving functions and components get added. The complex real driving system will deliver only about 60 to 70 percent accuracy performance on motion control for steering and acceleration, well short of what’s required for fully autonomous driving.
- Inability to cope well with complexity. Deterministic rules are usable in closed environments, such as a contained driving course, but can’t capture the complexity of real-world driving situations.
- Require too much data. Usually ML models require enormous amounts of data, which are too expensive and difficult to collect and move over existing corporate networks.
- Take up too much run-time, CPU/GPU processing and address exabytes of storage resources. It takes a lot of time and power to process the large volumes of automotive data and learn from them – and that’s often not cost-effective.
For the industry to evolve toward fully-autonomous driving, technologists have to develop an AI model that mirrors human driving behavior. In doing so, we need to guarantee a deterministic behavior that always produces the same result from the same input. The industry needs a new approach.
The big question then remains: How will the car act autonomously and intelligently in real time, in the real world?
We believe a big part of the answer lies in adapting knowledge of the human brain to AI – and we have drawn much of the inspiration for our new approach from brain science research conducted by Danko Nikolic at the Frankfurt Institute for Advanced Studies (FIAS) in Germany .
Adapting innovative brain research to AI and the production of fully autonomous vehicles has emerged as one of the more exciting technology innovation breakthroughs we’ve seen in the past couple of years.
While it will take time, the benefits to society of producing self-driving vehicles – and simply learning more about how the brain works along the way – holds great promise for human progress.