APIs have become ubiquitous with the advancement of mobility. All clients need to access data on the server and API’s define a contract to access that data.REST has been a popular way to expose data from a server after SOAP since it was lightweight and simple for clients. However, when the concept of REST was developed, client applications were relatively simple. With more rapid movements towards mobility, the client applications have grown in complexity and so has their data requirements from the server. And, REST APIs have shown to be too inflexible to keep up with the rapidly changing requirements of the clients that access them. And more often than not, it is very difficult to implement a fully REST compliant API. Most of the APIs are somewhat REST.
There are 2 major factors that have been challenging the way API’s are designed:
- Increased mobile usage calls for efficient data loading. With REST, you often have to make multiple calls to fetch the complete details of a resource.
- Variety of different frontend frameworks and platforms. Each platform has need of different representation of the same data. As a REST API developer, we mostly send all the data and leave it up to the client to ignore the data that is not needed. But this puts a load on the user’s data plan.
GraphQL, unlike REST, is a more efficient, flexible and powerful new option. The new API standard was developed and open-sourced by Facebook. It is now maintained by developers and open source community from all over the world.
It was developed to cope with the need for more flexibility and efficiency. It solves many of the shortcomings and inefficiencies that developers experience when interacting with REST APIs.
GraphQL enables declarative data fetching where a client can specify exactly what data they need. Instead of multiple endpoints, which return fixed data structure, there is a single endpoint which returns precise data that the client asked for.
To better understand the difference between GraphQL and the REST, let’s consider a blogging mobile application where we want to show a user’s profile screen with the following details on the screen:
User’s name
User’s All blogs title
User’s followers
Remember how we used to gather data with a REST API? It was typically done by accessing multiple endpoints. In the example, /users/<id> endpoint can be used to fetch the initial user data.
Also, it’s likely to have a /users/<id>/posts endpoint that will return all the posts for a user.
Next, the third endpoint will be /users/<id>/followers that will return a list of followers per user.
This leads to the client sending multiple calls, waiting on all those calls, chaining their responses, and gracefully handling if any one of the calls fails.
This highlights the first problem stated above.
Now coming to the second problem-
In this case, at the first step, we are fetching not only user’s name, which we need, but we are also fetching other data which is not required putting more load on the user’s data plan. Similarly, a lot of additional data is being sent across in other calls. This must be to support other clients like a corresponding web application which displays more information as the real estate available increases.
A possible solution within REST realm to solve the above problems would be that you could design your API in a way that exposes the data that is required by this particular profile page. But this is, again, not an optimal approach.
Why, you ask? Especially in today’s times, you want to be able to iterate quickly on your designs and experiment with different features. If you have to tweak your API every time you change your designs on the front end, you are not able to move fast. And keep in mind the versioning you would have to handle in your APIs to keep serving previous versions of your application. And you are in a mess.
Another elegant solution
In GraphQL on the other hand, you’d simply send a single query to the GraphQL server that includes the concrete data requirements. The server then responds with a JSON object where these requirements are fulfilled.
Here only a single request is sent to the server with the query in the request’s body with the exact data requirements and it will return the exact data needed by the application.
This solves our problems of over and under fetching.
I am sure many of you must have had this question in your mind-
An iOS app is so different from an Android app and miles apart from even the web app. How would we return different data for each client?
If I didn’t know about Graph QL, my solution would be either of 2:
- Let’s send all data required by either of apps and leave it on the application to parse as per their requirement. Over-fetching.
- Let’s create different endpoints or get platform information from the client in request header and return application specific data. On your path to maintainability issues.
GraphQL solves this problem by giving the power to clients to write their own queries to get data that they need. It’s generous that way- always taking the smallest possible request. Whereas, REST generally defaults to the fullest.
Some of the advantages of GraphQL are-
Typed schema
How many time has it happened that the API does not return data in the correct data type? Numbers and booleans are wrapped as a string. And then you debug it to find out the correct data type. This is because REST API contract only defines the data and not the types for that data.
In contrast, GraphQL uses a strong type system to define the capabilities of an API. All the types that are exposed in an API are written down in a schema using the GraphQL Schema Definition Language (SDL). This schema serves as the contract between the client and the server to define how a client can access the data.
GraphQL is a Query Language first
REST APIs are often created initially simple, then slowly more and more query language-like features are tacked on over time.
The most reasonable way to provide arguments for queries in REST is to shove them in the query string. Maybe a ?status=active to filter by status, then probably sort=created, but a client needs sort direction so sort-dir=desc is added. This is all taken care of in GraphQL because it is foremost a query language so you can easily add in query parameters without affecting the readability or creating a chaos of different types of queries.
{
human(id: “1000”) {
name
height(unit: FOOT)
}
}
GraphQL removes “Include vs Endpoint” indecision
Another customization consideration that comes up a lot is when to offer included relationships, and when to use another endpoint. This can be a difficult design choice, as you want your API to be flexible and performant, but includes used past the most trivial uses can be the opposite of that.
You start off with overly simplistic examples like /users?include=comments,posts but end up on /trips?include=driver,passengers,passengers.avatar,passengers.itineraries and worse.
REST would call for a HATEOAS approach, which would need you to make one call to the /trips endpoint, then hit “links”: { “driver”: “https://example.com/drivers/123” }, and again for passengers, and again for child data of each of those passengers.
This is a big win for GraphQL, as forcing the include approach, the GraphQL will be both efficient and consistent.
And now the disadvantages of GraphQL-
REST makes caching easier at all levels
In an endpoint-based API, clients can use HTTP caching to easily avoid re-fetching resources, and for identifying when two resources are the same. The URL in these APIs is a globally unique identifier that the client can leverage to build a cache. In GraphQL, though, there’s no URL-like primitive that provides this globally unique identifier for a given object. However, you can cache your GraphQL results at the front end using Apollo Client and Relay.
GraphQL query complexity
GraphQL doesn’t take away performance bottlenecks when you have to access multiple fields (authors, articles, comments) in one query. Whether the request was made in a RESTful architecture or GraphQL, the varied resources and fields still have to be retrieved from a data source. As a result, problems arise when a client requests too many nested fields at once. Frontend developers are not always aware of the work a server-side application has to perform to retrieve data, so there must be a mechanism like maximum query depths, query complexity weighting, avoiding recursion, or persistent queries for stopping inefficient requests from the other side.
So to conclude, GraphQL is a powerful technology to make the front end applications easier and more efficient. It has its pros and cons and should be taken into consideration when making important architectural decisions based on the specific use cases.

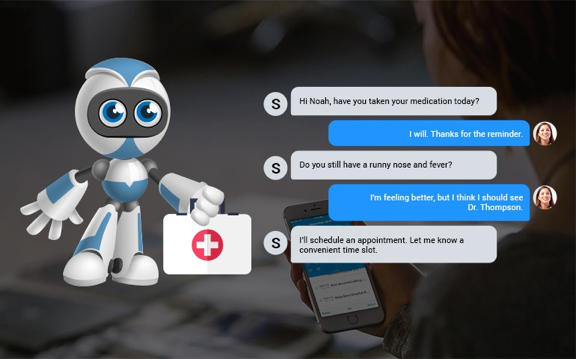
 The most challenging part for me was designing to handle the human-machine interaction. Each user is different. Unlike in websites/apps, where users can simply browse and leave, the chatbot users open the chat window to interact. They come with all sorts of questions- vague /smart /genuine /rogue /irrelevant and (sometimes) absurd. When they type a query, they expect the conversational UI to adapt to their needs–digest questions and construct intelligent answers/follow up questions.
The most challenging part for me was designing to handle the human-machine interaction. Each user is different. Unlike in websites/apps, where users can simply browse and leave, the chatbot users open the chat window to interact. They come with all sorts of questions- vague /smart /genuine /rogue /irrelevant and (sometimes) absurd. When they type a query, they expect the conversational UI to adapt to their needs–digest questions and construct intelligent answers/follow up questions.