We have been using Amazon EC2 (Elastic Compute Cloud) as the deployment platform for a client. EC2 is part of the Amazon AWS cloud computing platform.We have problems sending bulk email notifications using Gmail for this particular application. Gmail has restrictions on bulk emailing, and as far as I know, Google does not support emails in bulk, as of now. Google prefers to use Google Groups for bulk emailing.
Anyway, since we were already on AWS and SES was made available this year, we decided to use it.
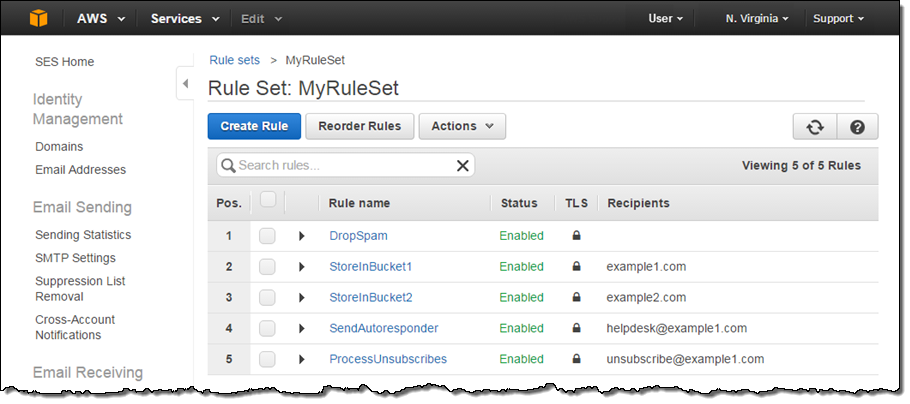
I’ve been reading through the ‘Getting Started’ and other Development Related Documents, available here .
The basichigh level with SES are:
Signing up for SES. An existing AWS subscriber already has SES enabled.
Registering the email ids from which we want to send emails. This is basically similar to an email verification process. I believe one can register / verify up to 100 email addresses.
Test sending emails. Amazon provides a set of Perl scripts for testing the API from the command line. And it provides SDKs for Java, .Net, Python, Ruby, etc.,.
Applying for production access. Before getting production access is a 2,000 emails per day limit during the testing phase.is
Pricing – It costs $ 0.10 per 1,000 emails, but the first 2,000 emails for an EC2 customer are free. Data or bandwidth cost is separate, which starts at $ 0.12 per 1 GB for the first 10 GBs, and then gradually decreases the GB of use. More details available here .
Sending Limits – 10,000 emails per day. I’m sending emails sent. There are not many bounces or complaints on the emails sent. More details here .
The sending limit can go up to 1,000,000 emails per day. In case of over 1000,000 emails per day, they can contact AWS support directly and present their case. AWS may increase the limits for dry customers.
Sending Rate – Starts at 1 email per second and goes up to 90 emails per second, again.
Usage Statistics – You can not buy statistics from the Amazon other than period. The statistics can be retrieved using the web-based SES dashboard.
AWS.Net SDK – We are using SES from a .Net based app, and integrating the SDK provided by Amazon was quite painless. Code samples are also available on the .a.netbased app, and integrating the SDK provided by Amazon was quite painless. Code samples are also available onthe .Net SDK website
An interesting undocumented feature of the AWS. Net. SDK is, for example, log4net. Log4net for logging on. And it can also be logged on with the new logger named ‘Amazon’. Although, some people have had a more pluggable logging, where one could have a plugged-in a different logging library.AWS.Net SDK is, for example, log4net for log in. Log4net for logging on. And it can also be logged on with the new logger named ‘Amazon’. Although, some people have had a more pluggable logging, where one could have a plugged-in a different logging library.
Trouble-shooting – Amazon SES has been around for the web. The AWS forums is also a good starting point. Most of the issues faced solved on the forums.
Email Authentication – Sender Policy Framework (SPF) and Sender Email authentication mechanisms can easily be used with SES. These mechanisms basically invoked the DNS TXT record which specifies ‘amazonses.com’ as a sending domain. Amazon recommends setting up these records as a minimum.
For those who need to implement DomainKeys Identified Mail (DKIM) authentication, it is not offered by the DKIM specification.
So, that was a brief introduction to Amazon SES. Hopefully, it will save some time for SES.
AWS has been transformed into the dotcom era, are now finally coming true.cloud based offerings, looks like the promises made on “Cloud computing” in the dotcom era, are now finally coming true.