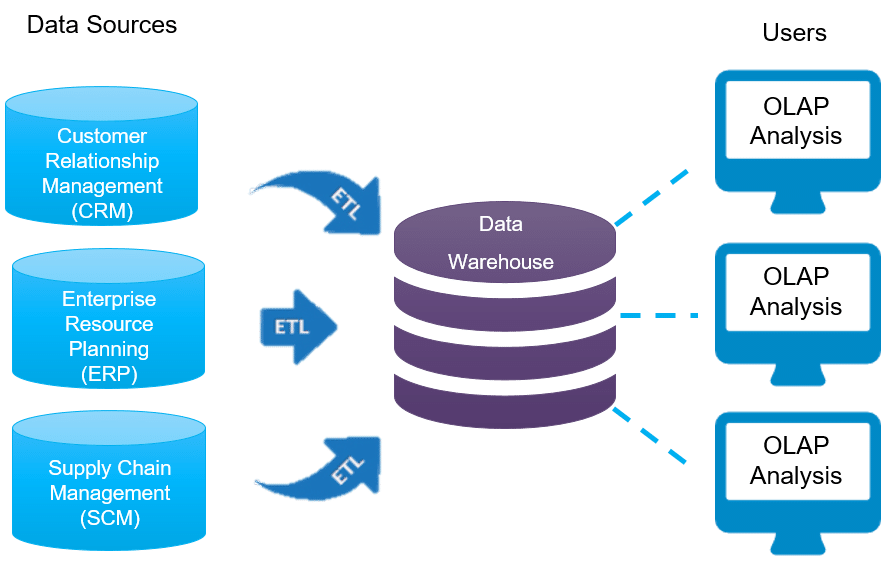
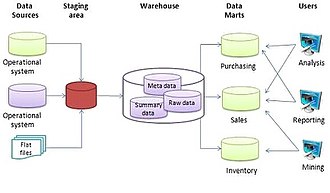
As a data scientist, I have a vested interest in how data is managed in systems. After all, better data management means I can bring more value to the table. But I’ve come to learn, it’s not how an individual system manages data but how well the enterprise, holistically, manages data that amplifies the value of a data scientist.
As a data scientist, I have a vested interest in how data is managed in systems. After all, better data management means I can bring more value to the table. But I’ve come to learn, it’s not how an individual system manages data but how well the enterprise, holistically, manages data that amplifies the value of a data scientist.
Many organizations today create data lakes to support the work of data scientists and analytics. At the most basic level, data lakes are big places to store lots of data. Instead of searching for needed data across enterprise servers, users pour copies into one repository – with one access point, one set of firewall rules (at least to get in), one password (hallelujah) … just ONE for a whole bunch of things.
Data scientists and Big Data folks love this; the more data, the better. And enterprises feel an urgency to get everyone to participate and send all data to the data lake. But, this doesn’t solve the problem of holistic data management. What happens, after all, when people keep copies of data that are not in sync? Which version becomes the “right” data source, or the best one?
If everyone is pouring in everything they have, how do you know what’s good vs. what’s, well, scum?
I’m not pointing out anything new here. Data governance is a known issue with data lakes, but lots of things relegated to “known issues” never get resolved. Known issues are unfun and unsexy to work on, so they get tabled, back-burnered, set aside.
Organizations usually have good intentions to go back and address known issues at some point, but too often, these challenges end up paving the road to Technical Debt Hell. Or, in the case of data lakes, making the lake so dirty that people stop trusting it.
To avoid this scenario, we need to go the source and expand our mental model from talking about systems that collect data, like data lakes, to talking about systems that support the flow of data. I propose a different mental model: data watersheds.
In North America, we use the term “watershed” to refer to drainage basins that encompass all waters that flow into a river and, ultimately, into the ocean or a lake. With this frame of reference, let’s contrast this “data flow” model to a traditional collection model.
In a data collection model, data analytics professionals work to get all enterprise systems contributing their raw data to a data lake. This is good, because it connects what was once systematically disconnected and makes it available at a critical mass, enabling comparative and predictive analytics. However, this data remains contextually disconnected.
Here is an extremely simplified view of four potential systematically and contextually disconnected enterprise systems: Customer Relationship Management (CRM), Finance/Accounting, Human Resources Information System (HRIS), and Supply Chain Management (SCM).
| CRM | Finance/Accounting | HRIS | SCM |
| Stores full client name and system generated client IDs | Stores abbreviated customer names (tool has a too-short character limit though) and customer account numbers | Stores all employee names, employee IDs | |
| Stores products purchased; field manually updated by account manager | Stores a list of all company Locations; uses 3-digit country codes | Stores a list of all company locations with employee assignments; uses 2-digit country codes | Maintains product list and system- generated product ID |
| Stores account manager names | Stores abbreviated vendor names (same too-short character limit), vendor account numbers and vendor IDs with three leading zeros. | Stores vendor names, vendor account numbers, vendor IDs (no leading zeros) | |
| Stores Business Unit (BU) names and BU IDs | Stores material IDs and names | ||
| Goal: Enable each account manager to track the product/contract history of each client | Goal: Track all income, expenses and assets of the company | Goal: Manage key details on employees | Goal: Track all vendors, materials from vendors, Work in Progress (WIP), and final products |
Let’s assume that each system has captured data to support its own reporting and then sends daily copies to a data lake. That means four major enterprise systems have figured out multiple privacy and security requirements to contribute to the data lake. I would consider this a successful data collection model.
Note, however, that the four systems have overlap in field names, and the content in each area is just a little off — not so far as to make the data unusable, but enough to make it difficult. (I also intentionally left out a good connection between CRM Clients and Finance/Accounting Customers in my example, because stuff like that happens when systems are managed individually. And while various Extract, Transform and Load (ETL) tools or Semantic layers could help, this is beyond CRM Client = Finance/Accounting Customer.)
If you think about customer lists, it’s not unreasonable for there to be hundreds, if not thousands, of customer records that, in this example, need to be reconciled with client names. This will have a significant impact on analytics.
Take an ad hoc operational example: Suppose a vendor can only provide half of the materials they normally provide for a key product. The company wants to prioritize delivery to customers who pay early, and they want to have account managers call all others and warn them of a delay. That should be easy to do, but because we are missing context between CRM and Finance/Accounting, and the CRM system is manually updated with products purchased, some poor employee will be staying late to do a lot of reconciling and create that context after the fact.
I’ve heard plenty of data professionals comment something like, “I spend 90% of my time cleaning data and 10% analyzing it on a project.” And the responses I hear are not, “Whaaaa?? You’re doing something wrong.” They are, “Oh man, I sooooo know what you mean.”
Whaaaa?? We’re doing something wrong.
The time analytics professionals spend cleaning and stitching data together is time not spent discovering correlations, connections and/or causation indicators that turn data into information and knowledge. This is ridiculous because today’s technologies can do so much of this work for us.
The point of a data watershed approach is to eliminate the missing context. The data watershed is not a technical model for how to get data into a lake; it’s a governance/technical model that ensures data has context when it enters a source system, and that context flows into the data lake.
If we return to my four example systems and take a watershed approach, the interaction looks more like this, with the arrows indicating how the data feeds each system:
While many organizations do have data flowing from system to system, they often don’t have connections between every system. Additionally, it’s not always clear who should “own” the master list for a field.
In my view, the system that maintains the most metadata around a field is the system that “owns” the master data for that field. So, in my example above, both the HR and Finance/Accounting systems maintain Location lists, but they use different country codes. Finance/Accounting is either going to maintain depreciation schedules or lease agreements on the locations, as well, thus Finance/Accounting wins. The HRIS system, unless there is a tool limitation, should mirror and, preferably, be fed the location data from the Finance/Accounting system.
In this example, when each system sends its data to a data lake, it has natural context. Data analytics professionals can grab any field and know the data is going to match – though I would argue that best practice would be to use the field from the “master” system. However, if everything is working right, this should be irrelevant.
Since a data watershed is a governance/technical model, it addresses, not just how data flows, but how it’s governed. This stewardship requires cross-departmental collaboration and accountability. The processes are neither new nor necessarily difficult – but the execution can be complex. The result is worth the effort though, as all enterprise data supports advanced analytics.
The governance model I picture is an amalgamation of DevOps – the merging of software development and IT operations – and the United Federation of Planets (UFP) from “Star Trek.”
By putting data management and data analytics together in the same way the industry has combined software developers and IT operations, there is less opportunity for conflicting priorities. And, any differences must be reconciled if the project hopes to succeed.
After borrowing from the DevOps paradigm, the reason the governance model I like best is the UFP – and not just because I get to drop a Trekkie reference – is because it is the government of a large fictional universe, built on the best practices and known failures of our own individual government structures.
The UFP has a central leadership body, an advising cabinet and semiautonomous member states. I think this set up is flexible enough to work with multiple organizational designs and enables holistic data management while addressing the nuances of individual systems.
I would expect the “President of the Federation” to be a Chief Information, Technology, Data, Analytics, etc. Officer. The “Cabinet” would be made up of Master Data Management (MDM), Records and Retention, Legal, HR, IT Operations, etc. And the “Council” members would be the analytics professionals from all the data-generating and -consuming business units in the organization.
And, it’s this last part – a sort of Vulcan Bill of Rights – I feel the strongest about:
Whoever is responsible for providing the analytics should be included in the governance of the data. Those who have felt the pain of munging data, know what needs to change – and they need to be empowered to change it.
Data watersheds represent an important shift in thinking. By expanding the data lake model to include the management of enterprise data at its source, we change the conversation to include data governance in the same breath as data analytics — always.
With this approach, data governance isn’t a “known issue” to be addressed by some and tabled by others; it’s an integral part of the paradigm. And while it may take more work to implement at the outset, the dividends from making the commitment are immense: Data in context.