An emerging way to program, known as low-code application development, is transforming the way we create software. With this new approach, we’re creating applications faster and more flexibly than ever before. What’s more, this work is being done by teams where up to three-quarters of the team members can have no prior experience in developing software.
Low-code development is one of the tools we deploy for our application services and solutions, which is a key component of our Enterprise Technology Stack. The approach is gaining traction. Research firm Gartner recently predicted that the worldwide market for low-code development technology will this year hit $13.8 billion, an increase over last year of nearly 23%. This rising demand for low-code technology is being driven by several factors, including the surge in remote development we have seen over the last year, digital disruption, hyper-automation and the rise of so-called composable businesses.
Low-code platforms are especially valuable to the public sector. Government IT groups need to be innovative and agile, yet they often struggle to be sufficiently responsive. Traditionally, they’ve developed applications using hard coding. While this approach offers a great deal of customization, it typically comes at the cost of long development times and high budgets. By comparison, low-code development is far faster, more agile and less costly.
With low-code platforms, public-sector developers no longer write all software code manually. Instead, they use visual “point-and-click” modeling tools — typically offered as a service in the cloud — to assemble web and mobile applications used by citizens. “Citizen developers” are a new breed of low-code programmers, who are potentially themselves public-sector end users, often with no prior development experience. The technology is relatively easy to learn and use.
Low-code tools are not appropriate for all projects. They’re best for developing software that involves limited volumes, simple workflows, straightforward processes and a predictable number of users. For these kinds of projects, we estimate that up to 80% of the development work can be done by citizen developers.
Experienced developers can benefit from using low-code tools, too. Over my own career of more than 30 years, I used traditional development methods three times to laboriously and methodically develop a mobile app. Now that I’ve adopted speedy low-code tools, I’ve already developed nine try-out mobile apps in just the last year.
Apps in a snap
To get a sense of just how quick working with low-code tools can be, consider a project we recently completed for the Government of Flanders. The project involves 96 vaccination centers the government is opening across Flanders. To track the centers’ inventories of vaccine doses and associated supplies, the government demanded a custom software application.
After a classical logistic software vendor passed on the project. We held our official kick-off meeting on Feb. 1, and just 18 days later, not only was our low-code inventory application up and running (with only a few open issues resolved in the subsequent days), but also the government’s first vaccination center was open for service. There’s no way we could have developed the application that quickly using traditional hard coding.
Low-code development can also be done with minimal staffing because all the ‘heavy lifting’ is done by the low-code environment. However, this is not an excuse to put new employees in charge of critical applications. Experienced staff are still needed to solve the classical issues of design, change management, planning, licenses, support, scoping and contracting.
We developed the Belgian vaccine inventory application with a code developer team of just two junior developers — one with the company for four months, the other for eight — working full time on the application. They were steered and supported by staff with more classical roles: a seasoned analyst, representative from the government, project manager, low-code (Microsoft) expert and solution architect. For these staff members, the low-code approach consumed only about 40% of their time.
Of course, we also leveraged agreements the government already had around Office 365 and Azure. But that’s yet another advantage of low-code software: It can exploit existing IT investments.

Finding flexibility
Flexibility is another big advantage of low-code development. In the context of software development, this means being able to make quick mid-course corrections. With traditional development tools, responding quickly to surprises that inevitably arise can be difficult if not impossible. But with low-code tools, making mid-course corrections is actually part of the original plan.
We had to make a mid-course correction when using low-code tools to develop an application to translate official government documents into all 18 languages spoken within Belgium.
Our first version of the software, despite using a reputable cognitive translation service, was missing three languages and providing sub-standard quality for another two. To fix this, our citizen developer — another new hire with no previous technical background — essentially clicked his way through the software’s workflows, integrated a second cognitive service from another supplier, and then created a dashboard indicating which of the two services the software should use when translating to a particular language.
Low-code development tools, when used in the right context, are fast, flexible and accessible to even first-time developers. And while these tools have their limitations and pitfalls, that’s seldom an excuse for not using them. Low-code tools are transforming how the public sector develops software, and we expect to see a lot more of it soon.

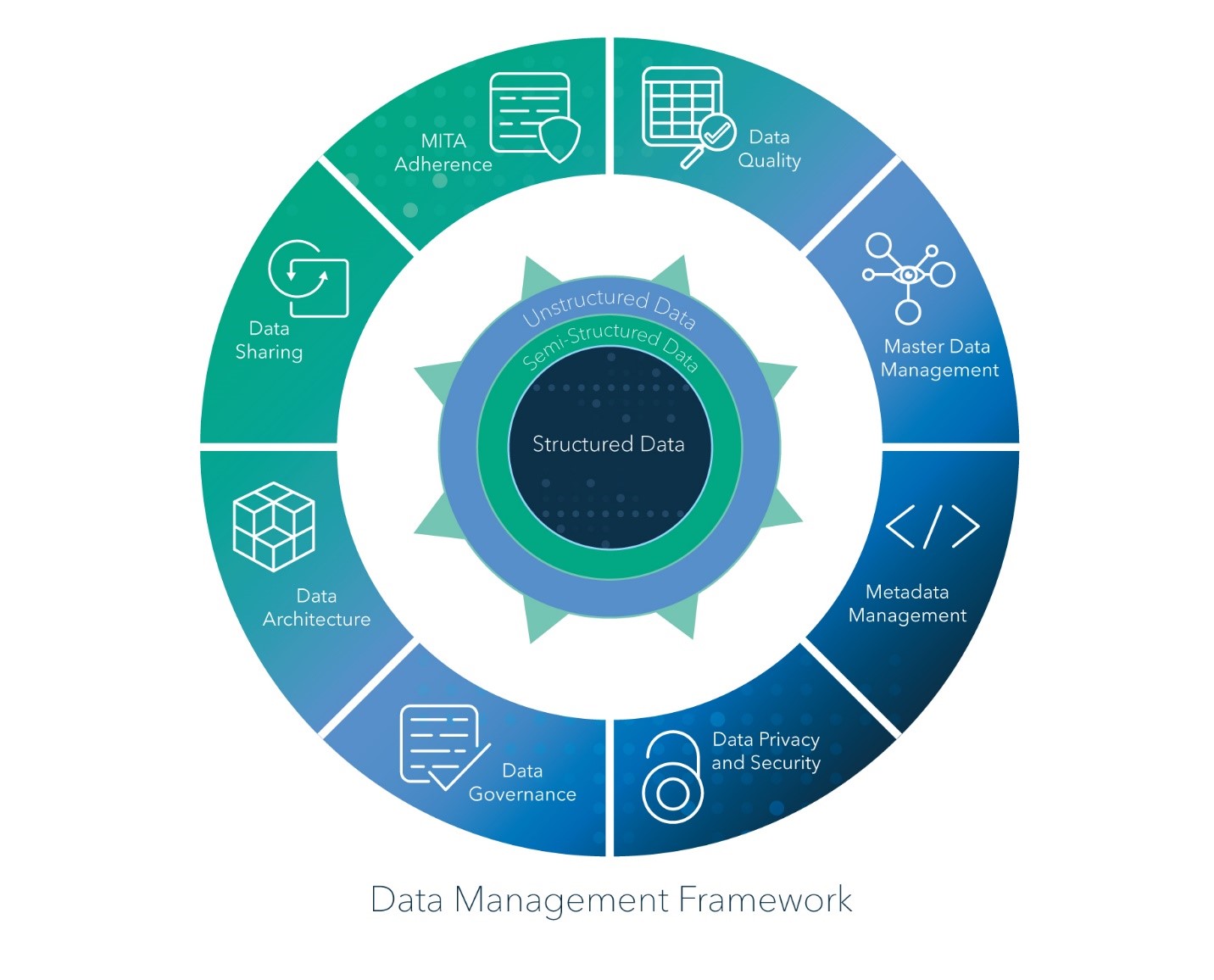
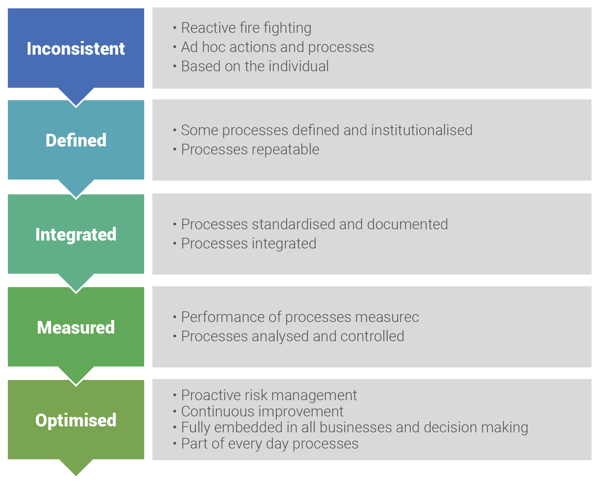
 As a data scientist, I have a vested interest in how data is managed in systems. After all, better data management means I can bring more value to the table. But I’ve come to learn, it’s not how an individual system manages data but how well the enterprise, holistically, manages data that amplifies the value of a data scientist.
As a data scientist, I have a vested interest in how data is managed in systems. After all, better data management means I can bring more value to the table. But I’ve come to learn, it’s not how an individual system manages data but how well the enterprise, holistically, manages data that amplifies the value of a data scientist.