Recently I had to stand up a Next Generation Firewall (NGF) in an Azure Subscription as part of a Minimum Viable Product (MVP). This was a Palo Alto NGF with a number of templates that can help with the implementation.
I had to alter the template so the Application Gateway was not deployed. The client had decided on a standard External Load Balancer (ELB) so the additional features of an Application Gateway were not required. I then updated the parameters in the JSON file and deployed via an AzureDevOps Pipeline, and with a few run-throughs in my test subscription, everything was successfully deployed.
That’s fine, but after going through the configuration I realized the public IPs (PIPs) deployed as part of the template were “Basic” rather than “Standard.” When you deploy an Azure Load Balancer, there needs to be parity with any device PIPs you are balancing against. So, the PIPs were deleted and recreated as “Standard.” Likewise, the Internal Load Balancer (ILB) needed this too.
I had a PowerShell script from when I had stood up load balancers in the past and I modified this to keep everything repeatable. There would be two NGFs in two regions – 4 NGFs in total and two external load-balancers and two internal load-balancers.
A diagram from one region is shown below:
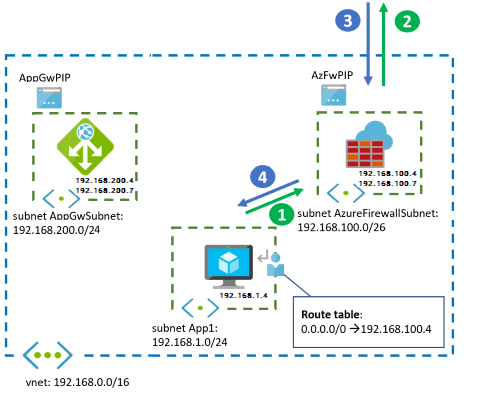
With all the load balancers in place, we should be able to pass traffic, right? Actually, no. Traffic didn’t seem to be passing. An investigation revealed several gotchas.
Gotcha 1. This wasn’t really a gotcha because I knew some Route Tables with User Defined Routing (UDR) would need to be set up. An example UDR on an internal subnet might be:
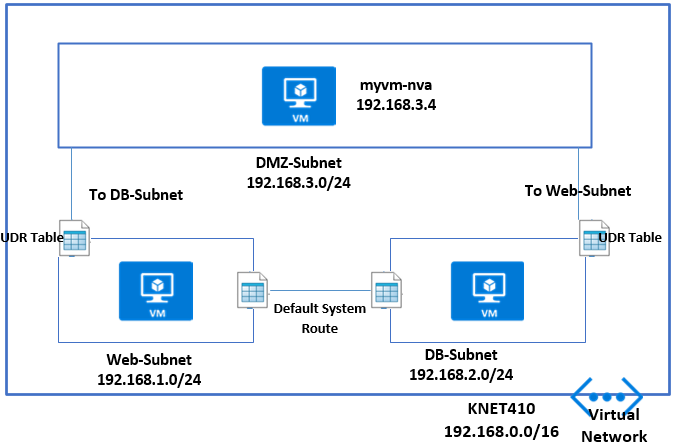
0.0.0.0/0 to Virtual Appliance pointing at the Private ILB IP Address. Also on the DMZ In subnet – where the Palo Alto Untrusted NIC sits, a UDR might be 0.0.0.0/0 to “Internet.” You should also have routes coming back the other way to the vNets. And, internally you can continue to allow Route Propagation if Express Route is in the mix, but on the Firewall Subnets, this should be disabled. Keep things tight and secure on those subnets.
But still no traffic after the Route Tables were configured.
Gotcha 2. The Palo Alto firewalls have a GUI ping utility in the user interface. Unfortunately, in the most current version of the Palo Alto Firewall OS (9 at the time of writing) the ping doesn’t work properly. This is because the firewall Interfaces are set to Dynamic Host Configuration Protocol (DHCP). I believe, as Azure controls and passes out the IPs to the Interfaces Static, DHCP is not required.
The way I decided to test things with this MVP, which is using a hub-and-spoke architecture, was to stand up a VM on a Non-Production Internal Spoke vNet.
Gotcha 3. With all my UDRs set up with the load balancers and an internal VM trying to browse the internet, things are still not working. I now call a Palo Alto architect for input and learn the configuration on the firewalls is fine but there’s something not right with the load balancers.
At this point I was tempted to go down the Outbound Rules configuration route at the Azure CLI. I had used this before when splitting UDP and TCP Traffic to different PIPs on a Standard Load Balancer.
But I decided to take a step back and to start going through the load balancer configuration. I noticed that on my Health Probe I had set it to HTTP 80 as I had used this previously.

I changed it from HTTP 80 to TCP 80 in the Protocol box to see if it made a difference. I did this on both internal and external load balancers.
Hey, presto. Web Traffic started passing. The Health Probe hadn’t liked HTTP as the protocol as it was looking for a file and path.
Ok, well and good. I revisited the Azure Architecture Guide from Palo Alto and also discussed with a Palo Alto architect.
They mentioned SSH – Port 22 for health probes. I changed that accordingly to see if things still worked – and they did.

Finding the culprit
So, the health probe was the culprit — as was I for re-using PowerShell from a previous configuration. Even then, I’m not sure my eye would have picked up HTTP 80 vs TCP 80 the first time round. The health probe couldn’t access HTTP 80 Path / so it basically stopped all traffic, whereas TCP 80 doesn’t look for a path. Now we are ready to switch the Route Table UDRs to point Production Spoke vNets to the NGF.
To sum up the three gotchas:
- Configure your Route Tables and UDRs.
- Don’t use Ping to test with Azure Load Balancers
- Don’t use HTTP 80 for your Health Probe to NGFs.
Hopefully this will help circumvent some problems configuring load balancers with your NGFs when you are standing up an MVP – whatever flavour of NGF is used.