Most government IT solutions were created only with the intention of automating the back office and focusing on efficiency. Requirements were gathered from case workers and then converted into functionality. The resulting IT solution is entirely focused on the internal operating model.
A similar approach has been taken with most government websites, which are often designed based on a government agency’s internal organisational structure, resulting in a poor user experience for citizens. Far too often, citizens start out on a promising home page, only to get lost in the weeds of dead-end pages, incorrect forms, and even other websites as they try in vain to navigate the unfamiliar organisational structure of the government agency.
But citizens no longer live in an analogue world and they’ve run out of patience. They expect governments to present digital citizen services in an easy-to-use, always-on, self-service, personal, and proactive way.
How to deliver a digital government experience

To deliver an experience that meets expectations, it’s clear that we need another approach — one centred around citizens. Requirements and functionality should be derived from the behaviour of the citizen as a customer – what information or service they need, what problem they need to solve, how they want to consume the content — and not from the organisational setup.
This also means that the government needs to provide a seamless and transparent interaction across channels. There is no time to develop a single application per service. Instead we must think in terms of platform models, where new services can be introduced quickly on top of existing services and a standard approach used to build applications.
This kind of transformation doesn’t just involve technology; it requires the transformation of the government organisation itself to improve how it provides services to its citizens via digital channels. It requires a strategy that is endorsed by the organisation’s leadership and mandates a transformation toward a new operating model, new capabilities and processes.
Balancing front- and back office digital programs

Going digital is not just about revisiting current processes and modernising legacy systems. It is also about balancing programs in the front and back office. This is a critical strategic point. Most digital programs are focused on improving the front office, i.e. the websites or apps that citizens interact with. That’s good insofar as it suggests a focus on citizen interactions. However, that model is unsustainable when the back office continues on as before – manual and labour-intensive, using the same legacy applications, and creating a backlog of requests.
Balance your digital programs with these five enablers
Some governments have already got the message and are redesigning their services with this model in mind. In the United Kingdom, for example, the government has published a set of best practices for designing a good citizen experience. The United States is following along the same lines.
Based on these design principles and drawing on our own experiences working with government organisations, Anteelo has identified five key enablers of successful citizen experience transformation:
Use design thinking. Also called human-centred design, design thinking is a creative problem-solving process that makes the citizen the central focus designing a better experience. It is ideal for tackling front-office related aspects.

Experiment in an agile way. Traditional approaches such as waterfall development take too long to deliver value. An agile, more iterative approach allows for the kinds of experimentation that can lead to process (and application) innovation in both the front- and back-office. This experimentation is a vital component of any digital journey and must be endorsed to get people, processes and technology aligned to optimise the workload.

Invest to drive automation. Governments can greatly benefit from introducing new technologies to automate administrative tasks and interconnect and then dynamically manage public infrastructure. Back-office applications can benefit from a surge in efficiency in applying RPA for example.

Get new digital capabilities. Having the right capabilities and people with knowledge and experience is key to executing a digital transformation program. No organisation will be able to introduce new technologies and change the operating model if it doesn’t have the right capabilities among its workforce.

Become data-driven. Government organisations that embrace data can transform services and become more predictive, proactive, preventive and personalised. Becoming a data-driven organisation also brings internal value. For one thing, greater efficiency means better utilisation of resources. Most of all, it brings value to citizens’ experiences by better understanding their behaviour and engaging them in meaningful interactions.

These enablers, of course, only describe a few key pieces of a more complex puzzle. We explore each enabler in considerably more depth and show how to turn each into concrete actions that drive better citizen outcomes, in our new white paper, Five enablers for governments to serve today’s digital citizens.




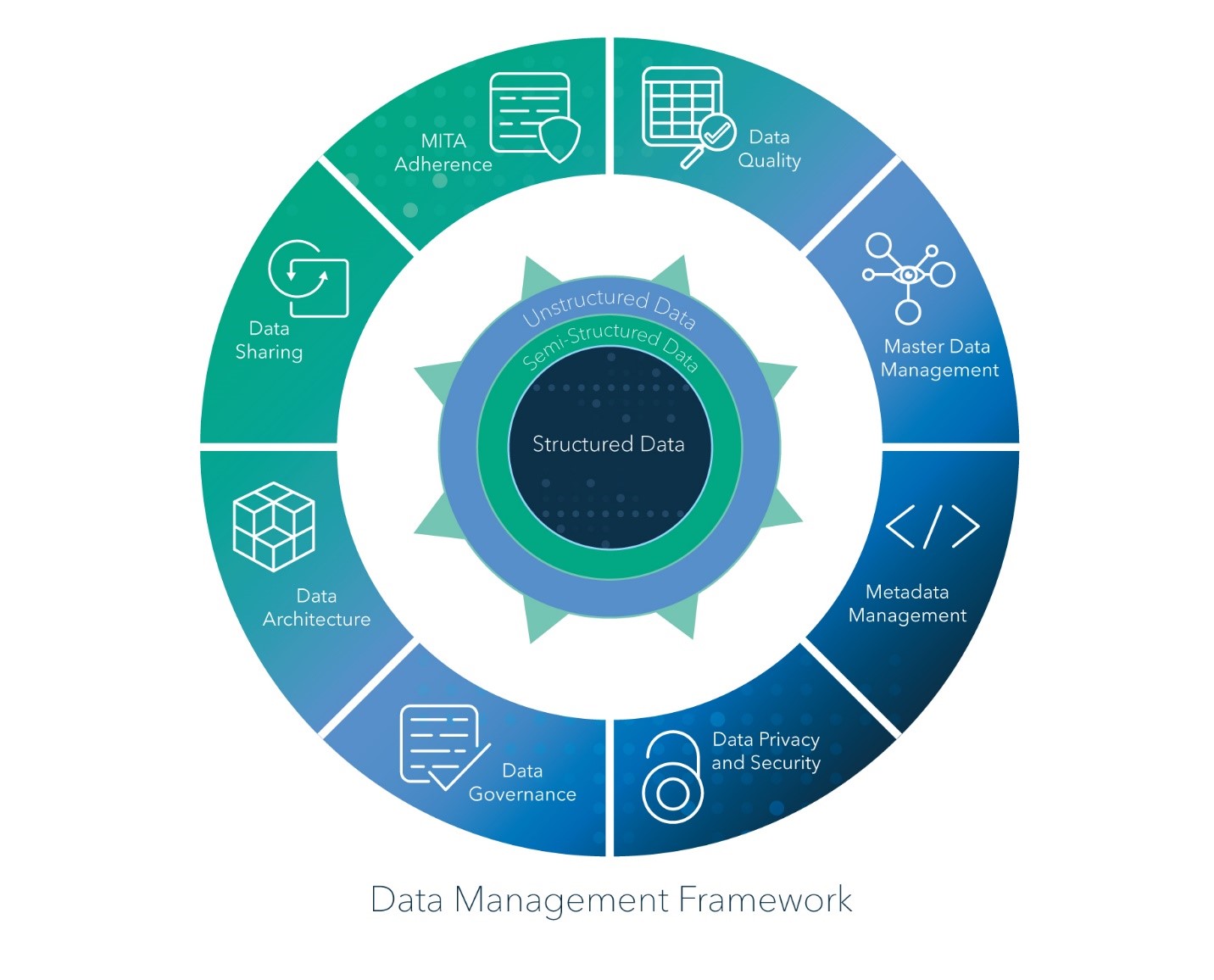
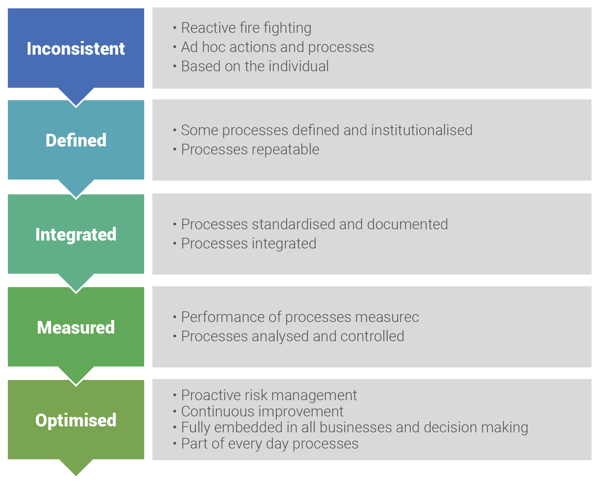
 As a data scientist, I have a vested interest in how data is managed in systems. After all, better data management means I can bring more value to the table. But I’ve come to learn, it’s not how an individual system manages data but how well the enterprise, holistically, manages data that amplifies the value of a data scientist.
As a data scientist, I have a vested interest in how data is managed in systems. After all, better data management means I can bring more value to the table. But I’ve come to learn, it’s not how an individual system manages data but how well the enterprise, holistically, manages data that amplifies the value of a data scientist.