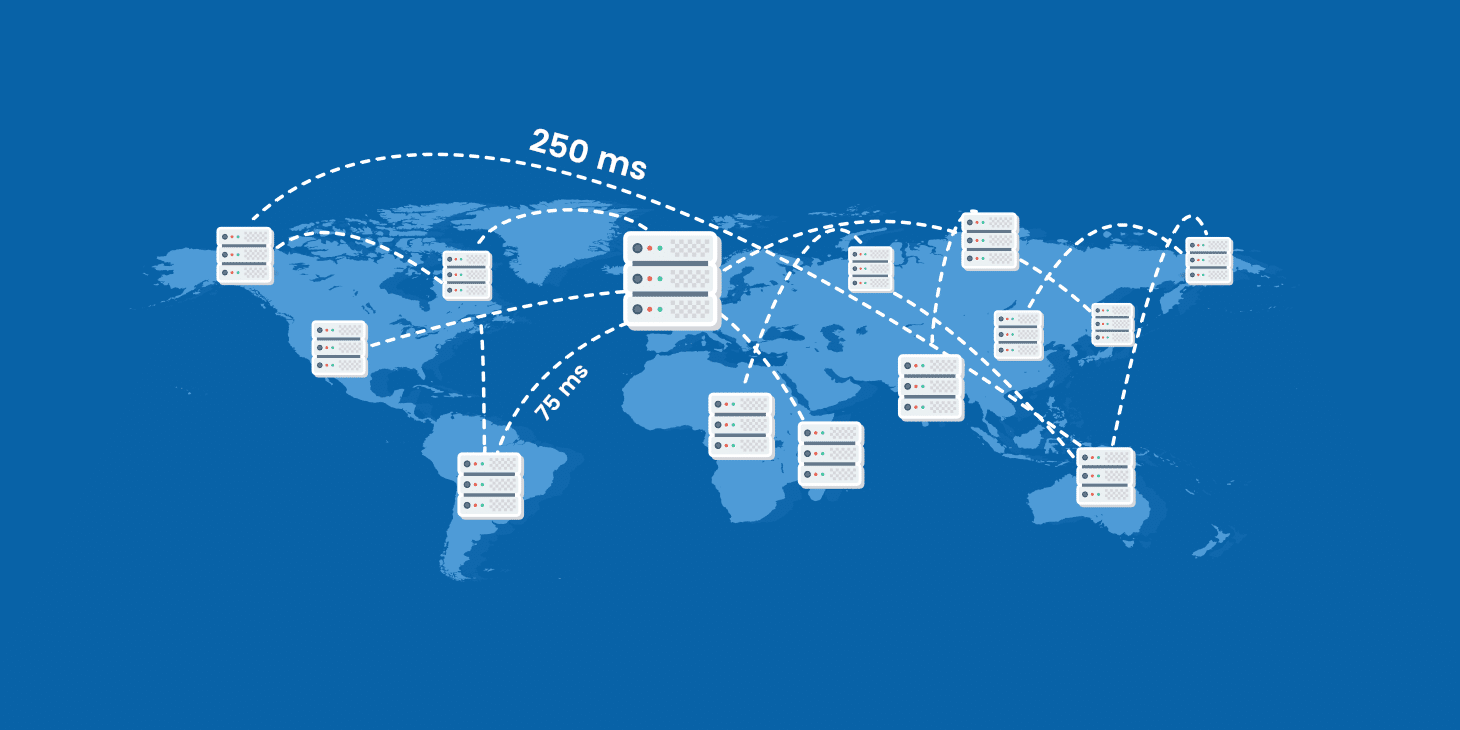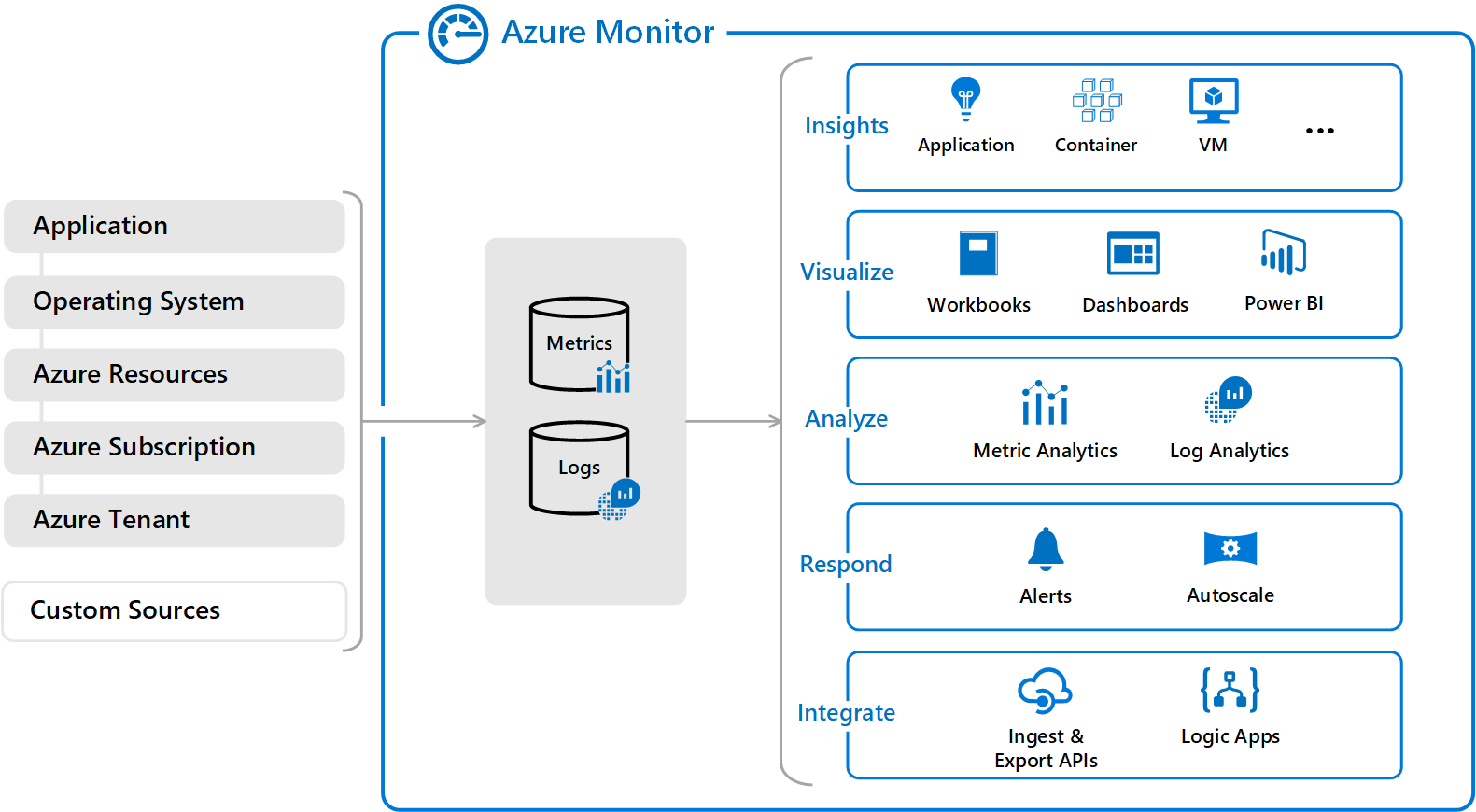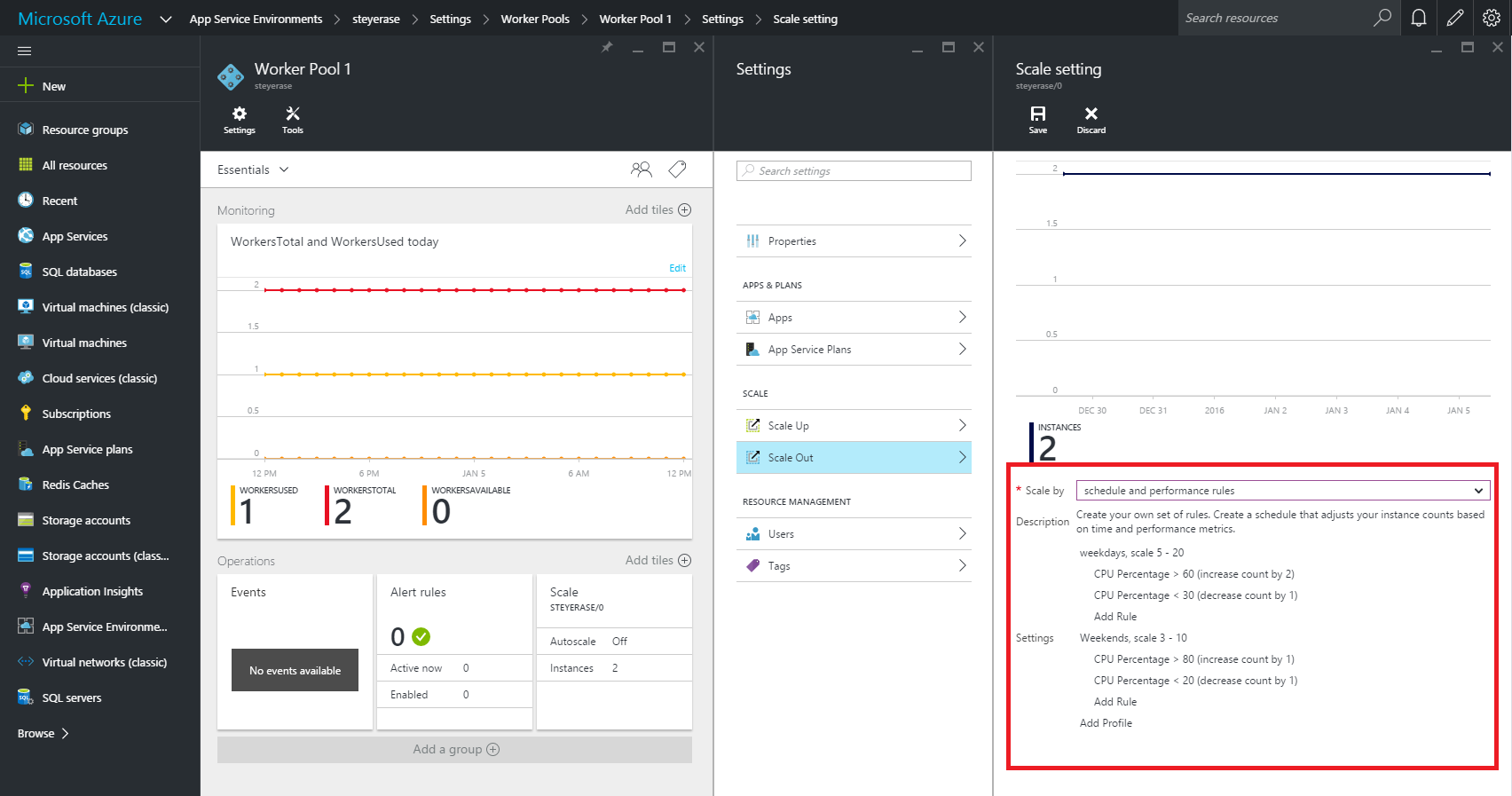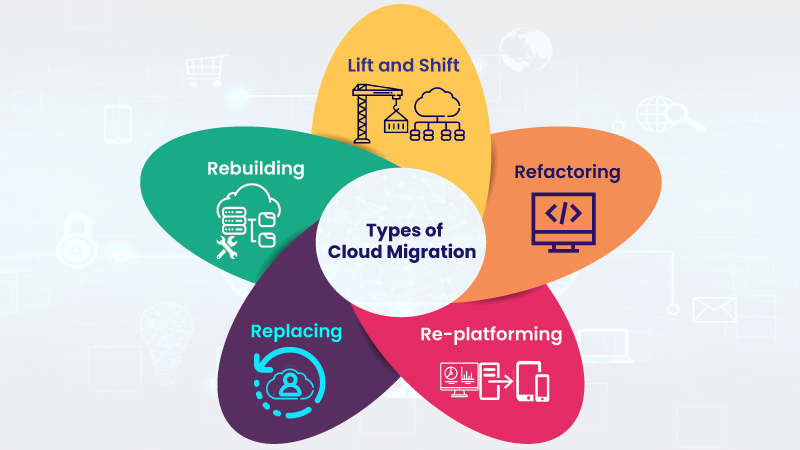
The easy approach to transitioning applications to the cloud is the simple “lift and shift” method, in which existing applications are simply migrated, as is, to a cloud-based infrastructure. And in some cases, this is a practical first step in a cloud journey. But in many cases, the smarter approach is to re-write and re-envision applications in order to take full advantage of the benefits of the cloud.
By rebuilding applications specifically for the cloud, companies can achieve dramatic results in terms of cost efficiency, improved performance and better availability. On top of that, re-envisioning applications enables companies to take advantage of the best technologies inherent in the cloud, like serverless architectures, and allows the company to tie application data into business intelligence systems powered by machine learning and AI.
Of course, not all applications can move to the cloud for a variety of regulatory, security and business process reasons. And not all applications that can be moved should be re-written because the process does require a cost and time commitment. The decision on which specific applications to re-platform and which to re-envision is a complex risk/benefit calculation that must be made on an application-by-application basis, but there are some general guidelines that companies should follow in their decision-making process.
What you need to consider

Before making any moves, companies need to conduct a basic inventory of their application portfolio. This includes identifying regulatory and compliance issues, as well as downstream dependencies to map out and understand how applications tie into each other in a business process or workflow. Another important task is to assess the application code and the platform the application runs on to determine how extensive a re-write is required, and the readiness and ability of the DevOps team to accomplish the task.
The next step is to prioritize applications by their importance to the business. In order to get the most bang for the buck, companies should focus on applications that have biggest business impact. For most companies, the priority has shifted from internal systems to customer-facing applications that might have special requirements, such as the ability to scale rapidly and accommodate seasonal demands, or the need to be ‘always available’. Many companies are finding their revenue generating applications were not built to handle these demands, so those should rise to the top of the list.
Re-platform vs. re-envision

There are some scenarios where lift and shift makes sense:
- Traditional data center. For many traditional, back-end data center applications, a simple lift and shift can produce distinct advantages in terms of cost savings and improved performance.
- Newly minted SaaS solution. There are many customer bases that have newer SaaS offerings available to them, but perhaps the functionality or integrated solutions that are a core part of their operations are in the early stages of a development cycle. Moving the currently installed solution to the cloud via a lift and shift is an appropriate modernization step – and can easily be transitioned to the SaaS solution when the organization is ready.
However, there are two more scenarios where lift and shift strategies work against digital transformation progress.

- Established SaaS solution. There is no justification, either in terms of cost or functionality, to remain on a legacy version of an application when there is a well-established SaaS solution.
- Custom written and highly customized applications. This scenario calls for a total re-write to the cloud in order to take advantage of cloud-native capabilities.
By re-writing applications as cloud-native, companies can slash costs, embed security into those application, and integrate multiple applications. Meanwhile, Windows Server 2008 and SQL Server 2008 end of life is fast approaching. Companies still utilizing these legacy systems will need to move applications off expiring platforms, providing the perfect impetus for modernizing now. There might be some discomfort associated with going the re-platform route, but the benefits are certainly worth the effort.